Notebook: run calibration
Preamble
Import packages
[1]:
# We import standard Python libraries
import numpy as np
import pandas as pd
import os
import geopandas as gpd
import matplotlib.pyplot as plt
from IPython.display import Image
# We also import our own packages
import inputs.data as inpdt
import inputs.parameters_and_options as inpprm
import equilibrium.compute_equilibrium as eqcmp
import equilibrium.functions_dynamic as eqdyn
import calibration.calib_main_func as calmain
import outputs.export_outputs as outexp
Define file paths
This corresponds to the architecture described in the README file (introduction tab of the documentation): the data folder is not hosted on the Github repository and should be placed in the root folder enclosing the repo.
[2]:
path_code = '..'
path_folder = path_code + '/Data/'
path_precalc_inp = path_folder + 'precalculated_inputs/'
path_data = path_folder + 'data_Cape_Town/'
path_precalc_transp = path_folder + 'precalculated_transport/'
path_scenarios = path_data + 'Scenarios/'
path_outputs = path_code + '/Output/'
path_floods = path_folder + "flood_maps/"
path_input_plots = path_outputs + 'input_plots/'
path_input_tables = path_outputs + 'input_tables/'
Create associated directories if needed
[3]:
try:
os.mkdir(path_input_plots)
except OSError as error:
print(error)
try:
os.mkdir(path_input_tables)
except OSError as error:
print(error)
[WinError 183] Cannot create a file when that file already exists: '../Output/input_plots/'
[WinError 183] Cannot create a file when that file already exists: '../Output/input_tables/'
Import parameters and options
We import default parameters and options
[4]:
import inputs.parameters_and_options as inpprm
options = inpprm.import_options()
param = inpprm.import_param(
path_precalc_inp, options)
We also set custom options for this simulation
We first set options regarding structural assumptions used in the model
[5]:
# Dummy for taking floods into account in agents' choices
options["agents_anticipate_floods"] = 1
# Dummy for preventing new informal settlement development
options["informal_land_constrained"] = 0
Then we set options regarding flood data used
[6]:
# Dummy for taking pluvial floods into account (on top of fluvial floods)
options["pluvial"] = 1
# Dummy for reducing pluvial risk for (better protected) formal structures
options["correct_pluvial"] = 1
# Dummy for taking coastal floods into account (on top of fluvial floods)
options["coastal"] = 1
# Digital elevation model to be used with coastal floods (MERITDEM or NASADEM)
# NB: MERITDEM is also the DEM used for fluvial and pluvial flood data
options["dem"] = "MERITDEM"
# Dummy for taking defended (vs. undefended) fluvial flood maps
# NB: FATHOM recommends to use undefended maps due to the high uncertainty
# in infrastructure modelling
options["defended"] = 0
# Dummy for taking sea-level rise into account in coastal flood data
# NB: Projections are up to 2050, based upon IPCC AR5 assessment for the
# RCP 8.5 scenario
options["climate_change"] = 0
We also set options for scenarios on time-moving exogenous variables
[7]:
# NB: Must be set to 1/2/3 for low/medium/high growth scenario
options["inc_ineq_scenario"] = 2
options["pop_growth_scenario"] = 3
options["fuel_price_scenario"] = 2
Finally, we set options regarding data processing
Default is set at zero to save computing time (data is simply loaded in the model).
NB: this is only needed to create the data for the first time, or when the source is changed, so that pre-processed data is updated.
[8]:
# Dummy for converting small-area-level (SAL) data into grid-level data
# (used for result validation)
options["convert_sal_data"] = 0
# Dummy for computing expected income net of commuting costs on the basis
# of calibrated wages
options["compute_net_income"] = 0
Load data
Basic geographic data
[9]:
import inputs.data as inpdt
grid, center = inpdt.import_grid(path_data)
amenities = inpdt.import_amenities(path_precalc_inp, options)
geo_grid = gpd.read_file(path_data + "grid_reference_500.shp")
geo_TAZ = gpd.read_file(path_data + "TAZ_ampp_prod_attr_2013_2032.shp")
Macro data
[10]:
import inputs.data as inpdt
(interest_rate, population, housing_type_data, total_RDP
) = inpdt.import_macro_data(param, path_scenarios, path_folder)
Households and income data
[11]:
import inputs.data as inpdt
income_class_by_housing_type = inpdt.import_hypothesis_housing_type()
(mean_income, households_per_income_class, average_income, income_mult,
income_baseline, households_per_income_and_housing
) = inpdt.import_income_classes_data(param, path_data)
# NB: we create this parameter to maintain money illusion in simulations
# (see eqsim.run_simulation function)
param["income_year_reference"] = mean_income
# Other data at SP (small place) level used for calibration and validation
(data_rdp, housing_types_sp, data_sp, mitchells_plain_grid_baseline,
grid_formal_density_HFA, threshold_income_distribution, income_distribution,
cape_town_limits) = inpdt.import_households_data(path_precalc_inp)
# Import nb of households per pixel, by housing type (from SAL data)
# NB: RDP housing is included in formal, and there are both formal and informal
# backyards
if options["convert_sal_data"] == 1:
housing_types = inpdt.import_sal_data(grid, path_folder, path_data,
housing_type_data)
housing_types = pd.read_excel(path_folder + 'housing_types_grid_sal.xlsx')
housing_types[np.isnan(housing_types)] = 0
Land use projections
[12]:
# We import basic projections
import inputs.data as inpdt
(spline_RDP, spline_estimate_RDP, spline_land_RDP,
spline_land_backyard, spline_land_informal, spline_land_constraints,
number_properties_RDP) = (
inpdt.import_land_use(grid, options, param, data_rdp, housing_types,
housing_type_data, path_data, path_folder)
)
# We correct areas for each housing type at baseline year for the amount of
# constructible land in each type
import inputs.data as inpdt
coeff_land = inpdt.import_coeff_land(
spline_land_constraints, spline_land_backyard, spline_land_informal,
spline_land_RDP, param, 0)
# We import housing heigth limits
import inputs.data as inpdt
housing_limit = inpdt.import_housing_limit(grid, param)
# We update parameter vector with construction parameters
# (relies on loaded data) and compute other variables
import inputs.parameters_and_options as inpprm
(param, minimum_housing_supply, agricultural_rent
) = inpprm.import_construction_parameters(
param, grid, housing_types_sp, data_sp["dwelling_size"],
mitchells_plain_grid_baseline, grid_formal_density_HFA, coeff_land,
interest_rate, options
)
Import flood data (takes some time when agents anticipate floods)
[13]:
# If agents anticipate floods, we return output from damage functions
import inputs.data as inpdt
if options["agents_anticipate_floods"] == 1:
(fraction_capital_destroyed, structural_damages_small_houses,
structural_damages_medium_houses, structural_damages_large_houses,
content_damages, structural_damages_type1, structural_damages_type2,
structural_damages_type3a, structural_damages_type3b,
structural_damages_type4a, structural_damages_type4b
) = inpdt.import_full_floods_data(options, param, path_folder)
# Else, we set those outputs as zero
# NB: 24014 is the number of grid pixels
elif options["agents_anticipate_floods"] == 0:
fraction_capital_destroyed = pd.DataFrame()
fraction_capital_destroyed["structure_formal_2"] = np.zeros(24014)
fraction_capital_destroyed["structure_formal_1"] = np.zeros(24014)
fraction_capital_destroyed["structure_subsidized_2"] = np.zeros(24014)
fraction_capital_destroyed["structure_subsidized_1"] = np.zeros(24014)
fraction_capital_destroyed["contents_formal"] = np.zeros(24014)
fraction_capital_destroyed["contents_informal"] = np.zeros(24014)
fraction_capital_destroyed["contents_subsidized"] = np.zeros(24014)
fraction_capital_destroyed["contents_backyard"] = np.zeros(24014)
fraction_capital_destroyed["structure_backyards"] = np.zeros(24014)
fraction_capital_destroyed["structure_formal_backyards"] = np.zeros(24014)
fraction_capital_destroyed["structure_informal_backyards"
] = np.zeros(24014)
fraction_capital_destroyed["structure_informal_settlements"
] = np.zeros(24014)
FU_5yr
FU_10yr
FU_20yr
FU_50yr
FU_75yr
FU_100yr
FU_200yr
FU_250yr
FU_500yr
FU_1000yr
P_5yr
P_10yr
P_20yr
P_50yr
P_75yr
P_100yr
P_200yr
P_250yr
P_500yr
P_1000yr
C_MERITDEM_0_0000
C_MERITDEM_0_0002
C_MERITDEM_0_0005
C_MERITDEM_0_0010
C_MERITDEM_0_0025
C_MERITDEM_0_0050
C_MERITDEM_0_0100
C_MERITDEM_0_0250
Contents in private formal
Contents in informal settlements
Contents in (any) backyard
Contents in formal subsidized
Private formal structures (one floor)
Private formal structures (two floors)
Formal subsidized structures (one floor)
Formal subsidized structures (two floors)
Informal settlement structures
Informal backyard structures
Formal backyard structures (one floor)
Formal backyard structures (two floors)
Import scenarios (for time-moving variables)
[14]:
import equilibrium.functions_dynamic as eqdyn
(spline_agricultural_price, spline_interest_rate,
spline_population_income_distribution, spline_inflation,
spline_income_distribution, spline_population,
spline_income, spline_minimum_housing_supply, spline_fuel
) = eqdyn.import_scenarios(income_baseline, param, grid, path_scenarios,
options)
Import income net of commuting costs (for all time periods)
[15]:
import inputs.data as inpdt
if options["compute_net_income"] == 1:
(incomeNetOfCommuting, modalShares, ODflows, averageIncome
) = inpdt.import_transport_data(
grid, param, 0, households_per_income_class, average_income,
spline_inflation, spline_fuel,
spline_population_income_distribution, spline_income_distribution,
path_precalc_inp, path_precalc_transp, 'GRID', options)
income_net_of_commuting_costs = np.load(
path_precalc_transp + 'GRID_incomeNetOfCommuting_0.npy')
Prepare data
Define dominant income group in each census block (SP)
[16]:
# In one case, we base our definition on the median income at the SP-level:
# we consider as dominant the group corresponding to the highest income
# threshold is crossed
if options["correct_dominant_incgrp"] == 0:
data_income_group = np.zeros(len(data_sp["income"]))
for j in range(0, param["nb_of_income_classes"] - 1):
data_income_group[data_sp["income"] >
threshold_income_distribution[j]] = j+1
# In the other case, we just consider the most numerous income group in each
# census block
elif options["correct_dominant_incgrp"] == 1:
data_income_group = np.zeros(len(income_distribution))
for i in range(0, len(income_distribution)):
data_income_group[i] = np.argmax(income_distribution[i])
Although the second option seems more logical, we take the first one as default since we are going to consider median SP prices, and we want associated net income to be in line with those values to avoid a sample selection bias in our regressions. Indeed, the purpose of such definition is to choose the right net income to estimate associated regressions.
Obtain number of formal private housing units per SP
NB: It is not clear whether RDP are included in SP formal count, and if they should be taken out based on imperfect cadastral estimations. For reference, we include the two options.
[17]:
if options["substract_RDP_from_formal"] == 1:
# We retrieve number of RDP units per SP from grid-level data
grid_intersect = pd.read_csv(path_data + 'grid_SP_intersect.csv',
sep=';')
# When pixels are associated to several SPs, we allocate them to the
# one with the biggest intersection area.
# NB: it would be more rigorous to split the number of RDP across
# SPs according to their respective intersection areas, but this is
# unlikely to change much
grid_intersect = grid_intersect.groupby('ID_grille').max('Area')
data_rdp["ID_grille"] = data_rdp.index
data_rdp["ID_grille"] = data_rdp["ID_grille"] + 1
rdp_grid = pd.merge(data_rdp, grid_intersect, on="ID_grille",
how="outer")
rdp_sp = rdp_grid.groupby('SP_CODE')['count'].sum()
rdp_sp = rdp_sp.reset_index()
rdp_sp = rdp_sp.rename(columns={'SP_CODE': 'sp_code'})
# We just fill the list with unmatched SPs to get the full SP vector
rdp_sp_fill = pd.merge(rdp_sp, data_sp['sp_code'], on="sp_code",
how="outer")
rdp_sp_fill['count'] = rdp_sp_fill['count'].fillna(0)
rdp_sp_fill = rdp_sp_fill.sort_values(by='sp_code')
data_number_formal = (
housing_types_sp.total_dwellings_SP_2011
- housing_types_sp.backyard_SP_2011
- housing_types_sp.informal_SP_2011
- rdp_sp_fill['count'])
elif options["substract_RDP_from_formal"] == 0:
data_number_formal = (
housing_types_sp.total_dwellings_SP_2011
- housing_types_sp.backyard_SP_2011
- housing_types_sp.informal_SP_2011
)
Given the uncertainty surrounding RDP counts, we take the second option as default and prefer to rely on sample selection (see below) to exclude the SPs where RDP housing is likely to drive most of our results.
Sample selection
As the relations we are going to estimate are only true for the formal private sector, we exclude SPs in the bottom quintile of property prices and for which more than 5% of households are reported to live in informal housing (settlements + backyards). We also exclude “rural” SPs (i.e., those that are large, with a small share than can be urbanized). This is more specific to the regression allowing us to estimate parameters of the construction function (fit on building density), hence the name of the selected_density variable.
We also add options to consider other criteria, namely we offer to exclude the poorest income group (which is in effect crowded out from the formal sector), as well as Mitchell’s Plain (as its housing market is very specific) and far-away land (where SPs are too big for aggregates to be representative of micro conditions).
[18]:
if options["correct_selected_density"] == 0:
selected_density = (
(data_sp["price"] > np.nanquantile(data_sp["price"], 0.2))
& (data_number_formal
> 0.95 * housing_types_sp.total_dwellings_SP_2011)
& (data_sp["unconstrained_area"]
< np.nanquantile(data_sp["unconstrained_area"], 0.8))
& (data_sp["unconstrained_area"] > 0.6 * 1000000 * data_sp["area"])
)
elif (options["correct_selected_density"] == 1
and options["correct_mitchells_plain"] == 0):
selected_density = (
(data_sp["price"] > np.nanquantile(data_sp["price"], 0.2))
& (data_number_formal
> 0.95 * housing_types_sp.total_dwellings_SP_2011)
& (data_sp["unconstrained_area"]
< np.nanquantile(data_sp["unconstrained_area"], 0.8))
& (data_sp["unconstrained_area"] > 0.6 * 1000000 * data_sp["area"])
& (data_income_group > 0)
& (data_sp["distance"] < 40)
)
elif (options["correct_selected_density"] == 1
and options["correct_mitchells_plain"] == 1):
selected_density = (
(data_sp["price"] > np.nanquantile(data_sp["price"], 0.2))
& (data_number_formal
> 0.95 * housing_types_sp.total_dwellings_SP_2011)
& (data_sp["unconstrained_area"]
< np.nanquantile(data_sp["unconstrained_area"], 0.8))
& (data_sp["unconstrained_area"] > 0.6 * 1000000 * data_sp["area"])
& (data_income_group > 0)
& (data_sp["mitchells_plain"] == 0)
& (data_sp["distance"] < 40)
)
We pick the second choice as our default since it is more conservative than the first, and less ad hoc than the third one.
Calibrate construction function parameters
[19]:
# We estimate construction function parameters based on a log-linearization
# of the housing market clearing condition
import calibration.calib_main_func as calmain
coeff_b, coeff_a, coeffKappa = calmain.estim_construct_func_param(
options, param, data_sp, threshold_income_distribution,
income_distribution, data_rdp, housing_types_sp,
data_number_formal, data_income_group, selected_density,
path_data, path_precalc_inp, path_folder)
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.665
Model: OLS Adj. R-squared: 0.657
Method: Least Squares F-statistic: 89.87
Date: Thu, 27 Apr 2023 Prob (F-statistic): 4.10e-32
Time: 13:06:39 Log-Likelihood: -52.613
No. Observations: 140 AIC: 113.2
Df Residuals: 136 BIC: 125.0
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const -3.7633 0.981 -3.837 0.000 -5.703 -1.824
x1 0.2415 0.069 3.483 0.001 0.104 0.379
x2 -0.8950 0.094 -9.533 0.000 -1.081 -0.709
x3 0.9949 0.070 14.283 0.000 0.857 1.133
==============================================================================
Omnibus: 50.298 Durbin-Watson: 1.587
Prob(Omnibus): 0.000 Jarque-Bera (JB): 164.414
Skew: -1.329 Prob(JB): 1.99e-36
Kurtosis: 7.596 Cond. No. 514.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[WinError 183] Cannot create a file when that file already exists: '../Data/precalculated_inputs/'
NB: The results are automatically saved for later use in simulations.
[20]:
# We update parameter vector
param["coeff_a"] = coeff_a
param["coeff_b"] = coeff_b
param["coeff_A"] = coeffKappa
# We print the calibrated values
print("coeff_a = " + str(param["coeff_a"]))
print("coeff_b = " + str(param["coeff_b"]))
print("coeff_A = " + str(param["coeff_A"]))
# We save them
# NB: coeff_a = 1 - coeff_b
np.save(path_precalc_inp + 'calibratedHousing_b.npy',
param["coeff_b"])
np.save(path_precalc_inp + 'calibratedHousing_kappa.npy',
param["coeff_A"])
coeff_a = 0.758489277045013
coeff_b = 0.241510722954987
coeff_A = 0.030595011996082885
Calibrate incomes and gravity parameter
We scan values for the gravity parameter to estimate incomes as a function of it. The value range is set by trial and error: the wider the range you want to test, the longer. In principle, we should find a value within a coarse interval before going to the finer level: this may require several iterations if the underlying data changes.
NB: We conduct scanning as it is too long and complex to run a solver directly.
Then, we select the income-gravity pair that best fits the distribution of commuters over distance from the CBD.
NB: We need to proceed in two steps as there is no separate identification of the gravity parameter and the net incomes.
[21]:
# We start by selecting the range over which we want to scan
if options["scan_type"] == "rough":
list_lambda = [13, 14, 15]
if options["scan_type"] == "normal":
list_lambda = np.arange(13.8, 14.3, 0.2)
if options["scan_type"] == "fine":
list_lambda = np.arange(13.94, 13.981, 0.02)
[22]:
# We then run the function that returns the calibrated outputs
# Note that depending on the precision level and the maximum number of
# iterations, this may take a while
import calibration.calib_main_func as calmain
(incomeCentersKeep, lambdaKeep, cal_avg_income, scoreKeep,
bhattacharyyaDistances) = (
calmain.estim_incomes_and_gravity(
param, grid, list_lambda, households_per_income_class,
average_income, income_distribution, spline_inflation, spline_fuel,
spline_population_income_distribution, spline_income_distribution,
path_data, path_precalc_inp, path_precalc_transp, options)
)
Estimating for lambda = 13.94
incomes for group 0
- computed - max error 0.009793095429407457
incomes for group 1
- computed - max error 0.009984196930170459
incomes for group 2
- computed - max error 0.009979443268550221
incomes for group 3
- computed - max error 0.006805194344302085
Estimating for lambda = 13.959999999999999
incomes for group 0
- computed - max error 0.00982765075950579
incomes for group 1
- computed - max error 0.009959790678248362
incomes for group 2
- computed - max error 0.00978892398854407
incomes for group 3
- computed - max error 0.009035639160528271
Estimating for lambda = 13.979999999999999
incomes for group 0
- computed - max error 0.00986212001327053
incomes for group 1
- computed - max error 0.00998395513933326
incomes for group 2
- computed - max error 0.009946364871984739
incomes for group 3
- computed - max error 0.007537367867095079
[23]:
# We update the parameter vector
param["lambda"] = np.array(lambdaKeep)
# We print the calibrated values (when possible)
print("lambda = " + str(param["lambda"]))
# We save them
np.save(path_precalc_inp + 'lambdaKeep.npy',
param["lambda"])
np.save(path_precalc_inp + 'incomeCentersKeep.npy',
incomeCentersKeep)
lambda = 13.959999999999999
Note that incomes are fitted to reproduce the observed distribution of jobs across income groups (in selected job centers), based on the commuting choice model.
Let us first visualize inputs
[24]:
# We import the employment data at the TAZ (transport zone) level
import outputs.export_outputs as outexp
jobsTable, selected_centers = outexp.import_employment_geodata(
households_per_income_class, param, path_data)
[25]:
# Then, we visualize number of jobs for income group 1
jobs_poor_2d = pd.merge(geo_TAZ, jobsTable["poor_jobs"],
left_index=True, right_index=True)
jobs_poor_2d = pd.merge(jobs_poor_2d, selected_centers,
left_index=True, right_index=True)
jobs_poor_2d.drop('geometry', axis=1).to_csv(
path_input_tables + 'jobs_poor' + '.csv')
jobs_poor_2d_select = jobs_poor_2d[
(jobs_poor_2d.geometry.bounds.maxy < -3740000)
& (jobs_poor_2d.geometry.bounds.maxx < -10000)].copy()
jobs_poor_2d_select.loc[
jobs_poor_2d_select["selected_centers"] == 0, 'jobs_poor'
] = 0
fig, ax = plt.subplots(figsize=(8, 10))
ax.set_axis_off()
plt.title("Number of poor jobs in selected job centers (data)")
jobs_poor_2d_select.plot(column='poor_jobs', ax=ax,
cmap='Reds', legend=True)
plt.savefig(path_input_plots + 'jobs_poor_in_selected_centers')
plt.close()
Image(path_input_plots + "jobs_poor_in_selected_centers.png")
[25]:
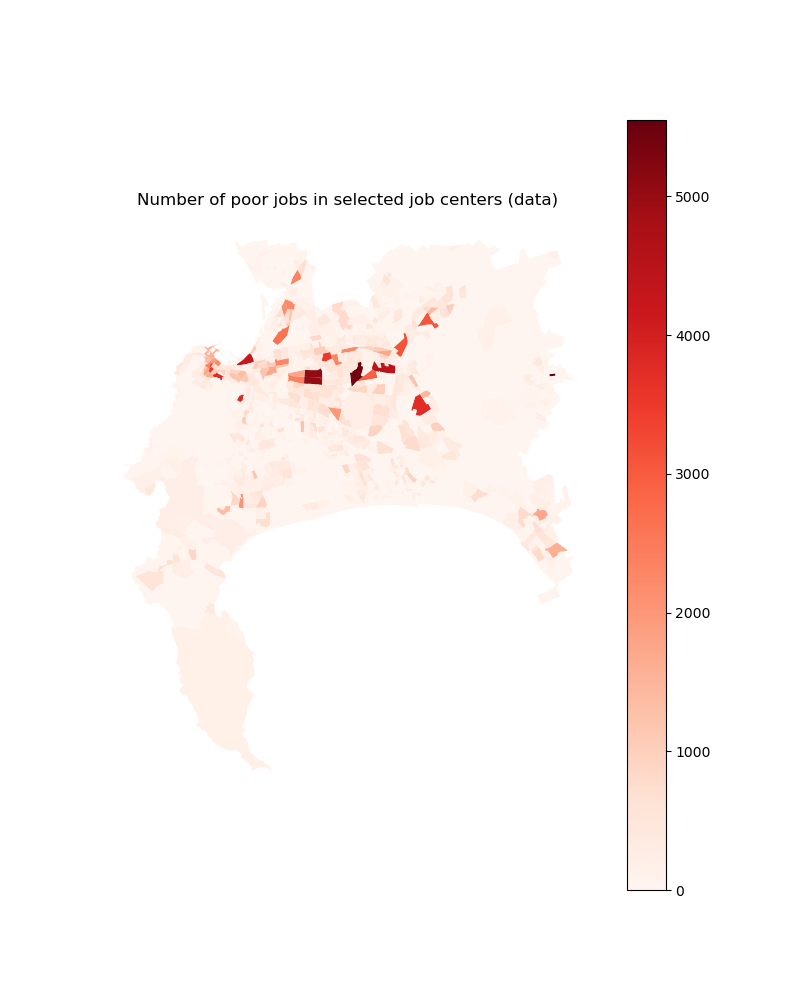
[26]:
# Then for income group 2
jobs_midpoor_2d = pd.merge(geo_TAZ, jobsTable["midpoor_jobs"],
left_index=True, right_index=True)
jobs_midpoor_2d = pd.merge(jobs_midpoor_2d, selected_centers,
left_index=True, right_index=True)
# jobs_midpoor_2d.to_file(path_tables + 'jobs_midpoor' + '.shp')
jobs_midpoor_2d.drop('geometry', axis=1).to_csv(
path_input_tables + 'jobs_midpoor' + '.csv')
jobs_midpoor_2d_select = jobs_midpoor_2d[
(jobs_midpoor_2d.geometry.bounds.maxy < -3740000)
& (jobs_midpoor_2d.geometry.bounds.maxx < -10000)].copy()
jobs_midpoor_2d_select.loc[
jobs_midpoor_2d_select["selected_centers"] == 0, 'jobs_midpoor'
] = 0
fig, ax = plt.subplots(figsize=(8, 10))
ax.set_axis_off()
plt.title("Number of midpoor jobs in selected job centers (data)")
jobs_midpoor_2d_select.plot(column='midpoor_jobs', ax=ax,
cmap='Reds', legend=True)
plt.savefig(path_input_plots + 'jobs_midpoor_in_selected_centers')
plt.close()
Image(path_input_plots + "jobs_midpoor_in_selected_centers.png")
[26]:
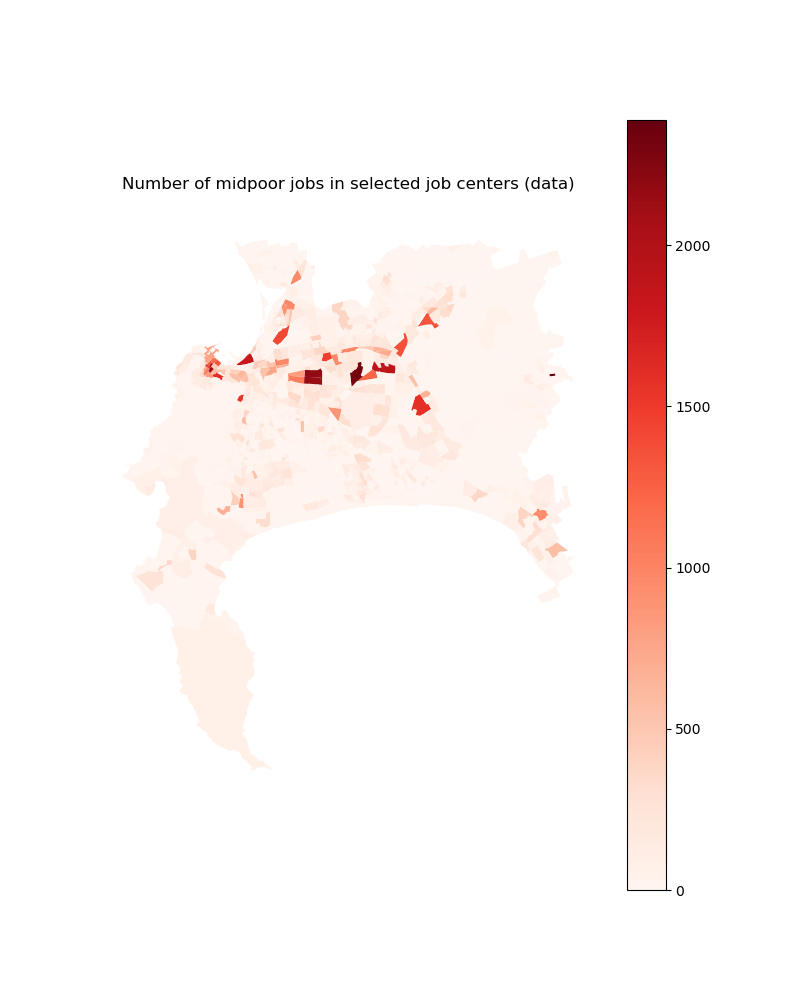
[27]:
# For income group 3
jobs_midrich_2d = pd.merge(geo_TAZ, jobsTable["midrich_jobs"],
left_index=True, right_index=True)
jobs_midrich_2d = pd.merge(jobs_midrich_2d, selected_centers,
left_index=True, right_index=True)
# jobs_midrich_2d.to_file(path_tables + 'jobs_midrich' + '.shp')
jobs_midrich_2d.drop('geometry', axis=1).to_csv(
path_input_tables + 'jobs_midrich' + '.csv')
jobs_midrich_2d_select = jobs_midrich_2d[
(jobs_midrich_2d.geometry.bounds.maxy < -3740000)
& (jobs_midrich_2d.geometry.bounds.maxx < -10000)].copy()
jobs_midrich_2d_select.loc[
jobs_midrich_2d_select["selected_centers"] == 0, 'jobs_midrich'
] = 0
fig, ax = plt.subplots(figsize=(8, 10))
ax.set_axis_off()
plt.title("Number of midrich jobs in selected job centers (data)")
jobs_midrich_2d_select.plot(column='midrich_jobs', ax=ax,
cmap='Reds', legend=True)
plt.savefig(path_input_plots + 'jobs_midrich_in_selected_centers')
plt.close()
Image(path_input_plots + "jobs_midrich_in_selected_centers.png")
[27]:
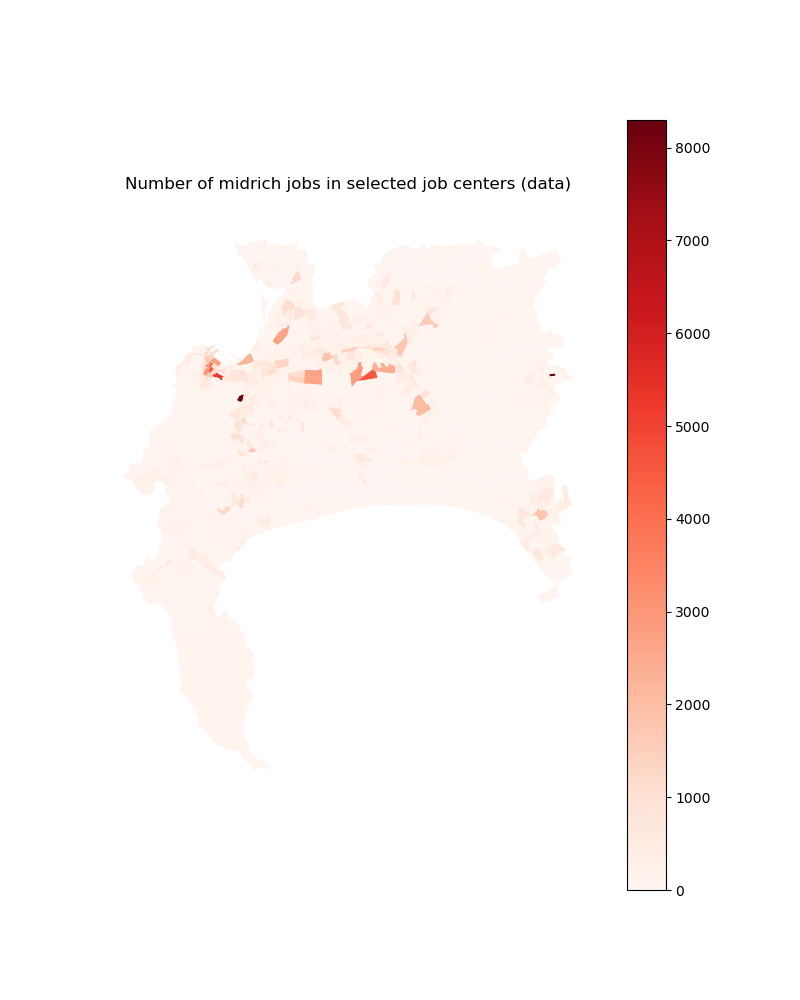
[28]:
# For income group 4
jobs_rich_2d = pd.merge(geo_TAZ, jobsTable["rich_jobs"],
left_index=True, right_index=True)
jobs_rich_2d = pd.merge(jobs_rich_2d, selected_centers,
left_index=True, right_index=True)
# jobs_rich_2d.to_file(path_tables + 'jobs_rich' + '.shp')
jobs_rich_2d.drop('geometry', axis=1).to_csv(
path_input_tables + 'jobs_rich' + '.csv')
jobs_rich_2d_select = jobs_rich_2d[
(jobs_rich_2d.geometry.bounds.maxy < -3740000)
& (jobs_rich_2d.geometry.bounds.maxx < -10000)].copy()
jobs_rich_2d_select.loc[
jobs_rich_2d_select["selected_centers"] == 0, 'jobs_rich'
] = 0
fig, ax = plt.subplots(figsize=(8, 10))
ax.set_axis_off()
plt.title("Number of rich jobs in selected job centers (data)")
jobs_rich_2d_select.plot(column='rich_jobs', ax=ax,
cmap='Reds', legend=True)
plt.savefig(path_input_plots + 'jobs_rich_in_selected_centers')
plt.close()
Image(path_input_plots + "jobs_rich_in_selected_centers.png")
[28]:
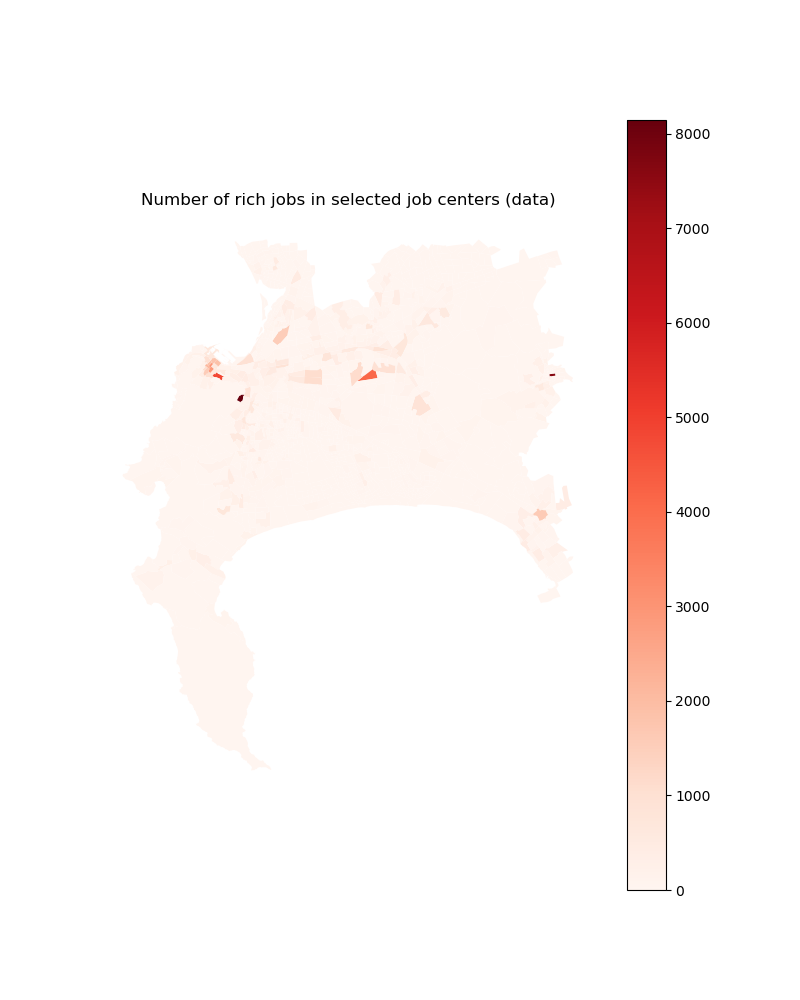
We visualize the associated calibrated outputs
[29]:
# We first load and rearrange the data that we just computed
income_centers_init = np.load(
path_precalc_inp + 'incomeCentersKeep.npy')
income_centers_init[income_centers_init < 0] = 0
income_centers_init_merge = pd.DataFrame(income_centers_init)
income_centers_init_merge = income_centers_init_merge.rename(
columns={income_centers_init_merge.columns[0]: 'poor_income',
income_centers_init_merge.columns[1]: 'midpoor_income',
income_centers_init_merge.columns[2]: 'midrich_income',
income_centers_init_merge.columns[3]: 'rich_income'})
income_centers_init_merge["count"] = income_centers_init_merge.index + 1
[30]:
# We prepare, execute, and clean the merge with geographic grid
selected_centers_merge = selected_centers.copy()
(selected_centers_merge["count"]
) = selected_centers_merge.selected_centers.cumsum()
selected_centers_merge.loc[
selected_centers_merge.selected_centers == 0, "count"] = 0
income_centers_TAZ = pd.merge(income_centers_init_merge,
selected_centers_merge,
how='right', on='count')
income_centers_2d = pd.merge(geo_TAZ, income_centers_TAZ,
left_index=True, right_index=True)
income_centers_2d.drop('geometry', axis=1).to_csv(
path_input_tables + 'income_centers_2d' + '.csv')
income_centers_2d_select = income_centers_2d[
(income_centers_2d.geometry.bounds.maxy < -3740000)
& (income_centers_2d.geometry.bounds.maxx < -10000)].copy()
[31]:
# We then visualize calibrated incomes for income group 1
fig, ax = plt.subplots(figsize=(8, 10))
ax.set_axis_off()
plt.title("Annual incomes (in R) per job center for poor households")
income_centers_2d_select.plot(column='poor_income', ax=ax,
cmap='Reds', legend=True)
plt.savefig(path_input_plots + 'poor_income_in_selected_centers')
plt.close()
Image(path_input_plots + "poor_income_in_selected_centers.png")
[31]:
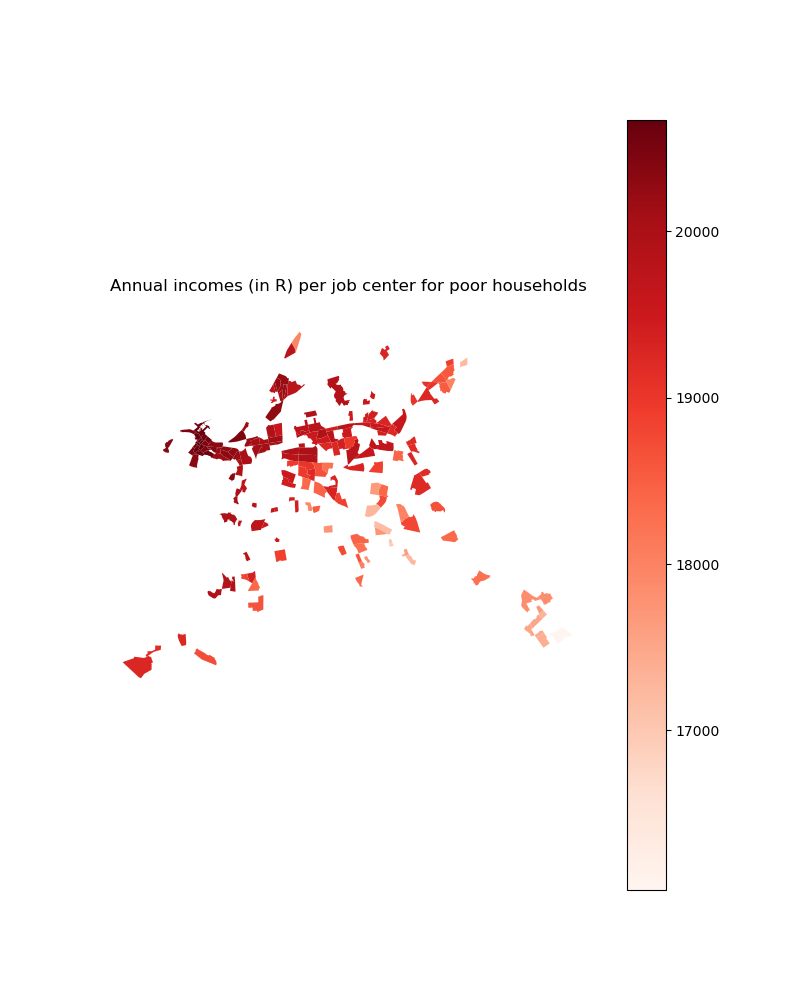
[32]:
# For income group 2
fig, ax = plt.subplots(figsize=(8, 10))
ax.set_axis_off()
plt.title("Annual incomes (in R) per job center for midpoor households")
income_centers_2d_select.plot(column='midpoor_income', ax=ax,
cmap='Reds', legend=True)
plt.savefig(path_input_plots + 'midpoor_income_in_selected_centers')
plt.close()
Image(path_input_plots + "midpoor_income_in_selected_centers.png")
[32]:
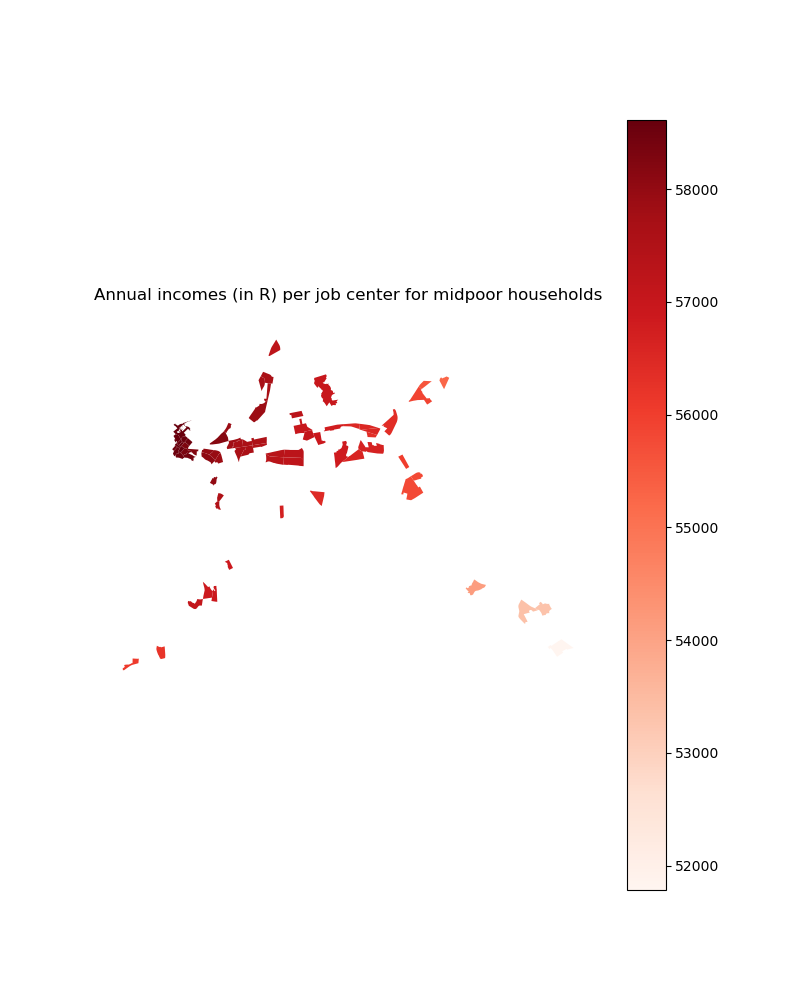
[33]:
# For income group 3
fig, ax = plt.subplots(figsize=(8, 10))
ax.set_axis_off()
plt.title("Annual incomes (in R) per job center for midrich households")
income_centers_2d_select.plot(column='midrich_income', ax=ax,
cmap='Reds', legend=True)
plt.savefig(path_input_plots + 'midrich_income_in_selected_centers')
plt.close()
Image(path_input_plots + "midrich_income_in_selected_centers.png")
[33]:
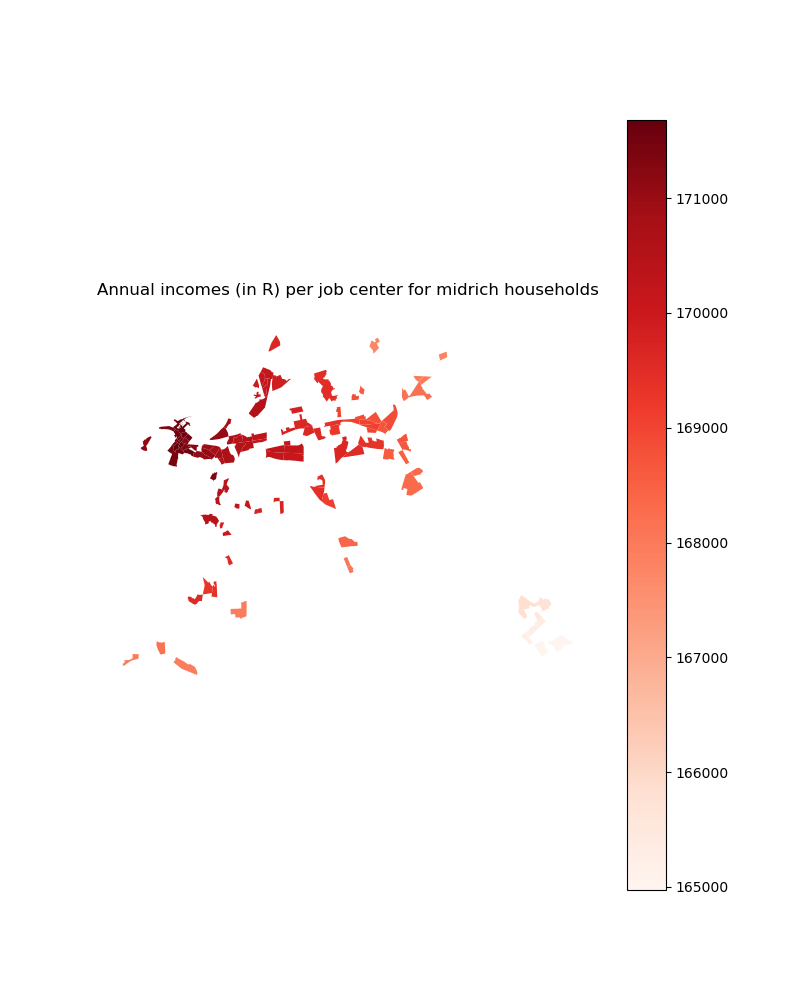
[34]:
# For income group 4
fig, ax = plt.subplots(figsize=(8, 10))
ax.set_axis_off()
plt.title("Annual incomes (in R) per job center for rich households")
income_centers_2d_select.plot(column='rich_income', ax=ax,
cmap='Reds', legend=True)
plt.savefig(path_input_plots + 'rich_income_in_selected_centers')
plt.close()
Image(path_input_plots + "rich_income_in_selected_centers.png")
[34]:
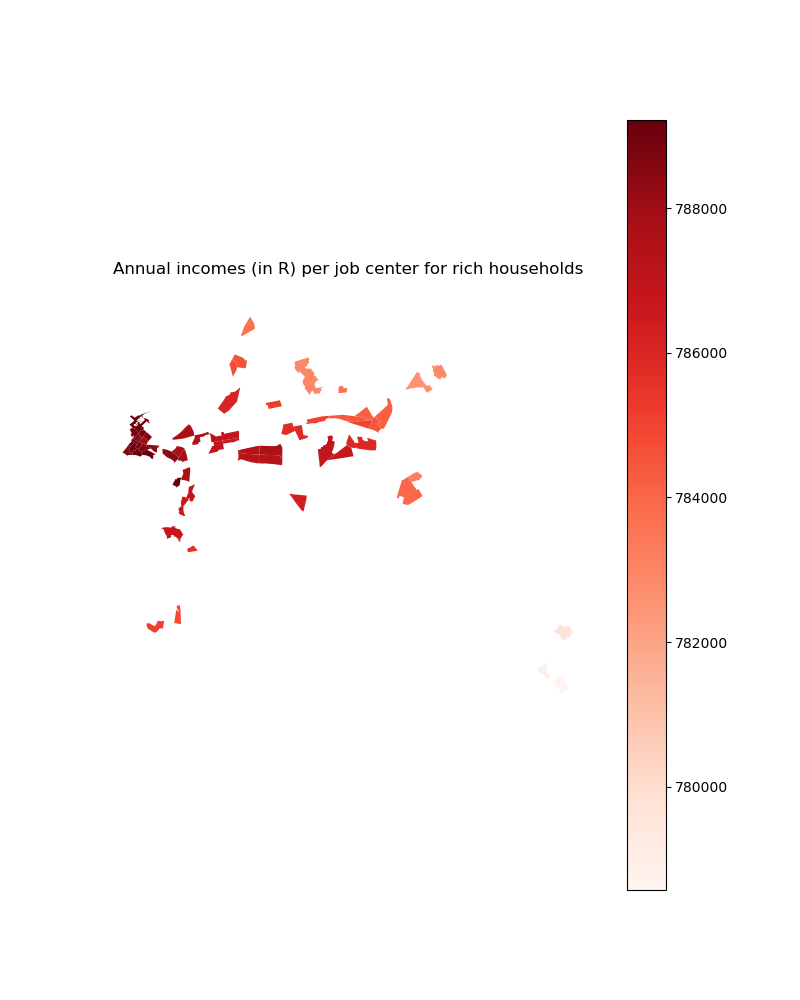
Calibrate utility function parameters
We compute local incomes net of commuting costs at the SP (not grid) level that is used in calibration.
[35]:
# Note that lambda and calibrated incomes have an impact here: from now on,
# we will stop loading precalibrated parameters to rely on the newly
# calibrated parameters that we just saved
options["load_precal_param"] = 0
import inputs.data as inpdt
(incomeNetOfCommuting, *_
) = inpdt.import_transport_data(
grid, param, 0, households_per_income_class, average_income,
spline_inflation, spline_fuel,
spline_population_income_distribution, spline_income_distribution,
path_precalc_inp, path_precalc_transp, 'SP', options)
Then we calibrate utility function parameters based on the maximization of a composite likelihood that reproduces the fit on exogenous amenities, dwelling sizes, and income sorting.
[36]:
# NB: Here, we also have an impact from construction parameters and sample
# selection (+ number of formal units)
import calibration.calib_main_func as calmain
(calibratedUtility_beta, calibratedUtility_q0, cal_amenities, u3, u4
) = calmain.estim_util_func_param(
data_number_formal, data_income_group, housing_types_sp, data_sp,
coeff_a, coeff_b, coeffKappa, interest_rate,
incomeNetOfCommuting, path_data, path_precalc_inp,
options, param)
Start scanning
Scanning complete
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.160
Model: OLS Adj. R-squared: 0.134
Method: Least Squares F-statistic: 6.268
Date: Thu, 27 Apr 2023 Prob (F-statistic): 4.06e-08
Time: 13:13:52 Log-Likelihood: 5.1856
No. Observations: 307 AIC: 9.629
Df Residuals: 297 BIC: 46.90
Df Model: 9
Covariance Type: nonrobust
==============================================================================================
coef std err t P>|t| [0.025 0.975]
----------------------------------------------------------------------------------------------
const -0.4580 0.038 -11.975 0.000 -0.533 -0.383
distance_distr_parks -0.0509 0.043 -1.178 0.240 -0.136 0.034
distance_ocean 0.0625 0.041 1.522 0.129 -0.018 0.143
distance_ocean_2_4 0.0105 0.046 0.231 0.818 -0.079 0.101
distance_urban_herit 0.1845 0.052 3.562 0.000 0.083 0.286
airport_cone2 -0.0070 0.067 -0.105 0.916 -0.138 0.124
slope_1_5 0.1444 0.034 4.251 0.000 0.078 0.211
slope_5 0.1209 0.049 2.489 0.013 0.025 0.216
distance_biosphere_reserve 0.0977 0.038 2.576 0.010 0.023 0.172
distance_train 0.0386 0.035 1.101 0.272 -0.030 0.107
==============================================================================
Omnibus: 192.573 Durbin-Watson: 1.351
Prob(Omnibus): 0.000 Jarque-Bera (JB): 1519.449
Skew: -2.562 Prob(JB): 0.00
Kurtosis: 12.620 Cond. No. 6.56
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[37]:
# We update parameter vector
param["beta"] = calibratedUtility_beta
param["q0"] = calibratedUtility_q0
# We print calibrated values (when possible)
print("beta = " + str(param["beta"]))
print("q0 = " + str(param["q0"]))
# We save them
# NB : alpha = 1 - beta
np.save(path_precalc_inp + 'calibratedUtility_beta.npy',
param["beta"])
np.save(path_precalc_inp + 'calibratedUtility_q0.npy',
param["q0"])
np.save(path_precalc_inp + 'calibratedAmenities.npy',
cal_amenities)
beta = 0.2533234103077873
q0 = 3.9713721908703206
Calibrate disamenity index for informal backyards + settlements
[38]:
# We first need to recompute income net of commuting costs at baseline
# year since calibrated income has changed
import inputs.data as inpdt
(incomeNetOfCommuting, modalShares, ODflows, averageIncome
) = inpdt.import_transport_data(
grid, param, 0, households_per_income_class, average_income,
spline_inflation, spline_fuel,
spline_population_income_distribution, spline_income_distribution,
path_precalc_inp, path_precalc_transp, 'GRID', options)
income_net_of_commuting_costs = np.load(
path_precalc_transp + 'GRID_incomeNetOfCommuting_0.npy')
[39]:
# Then, we do the same for the amenity index (calibrated values normalized around 1)
import inputs.data as inpdt
amenities = inpdt.import_amenities(path_precalc_inp, options)
[40]:
# Let us visualize the calibrated amenity index
import outputs.export_outputs as outexp
amenity_map = outexp.export_map(
amenities, grid, geo_grid, path_input_plots, 'amenity_map',
"Amenity score map (from .01 to .99 percentile)",
path_input_tables,
ubnd=np.quantile(amenities, 0.9999),
lbnd=np.quantile(amenities, 0.0001))
Image(path_input_plots + "amenity_map.png")
amenity_map done
[40]:
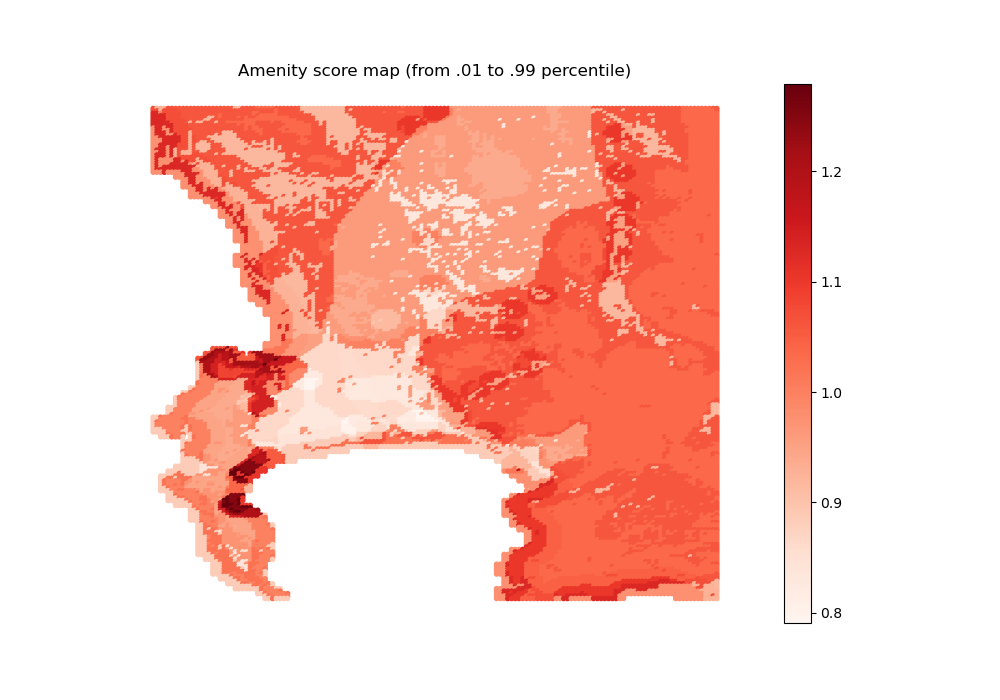
Note the the local amenity index is only as good as the underlying exogenous amenity covariates used for prediction: this can be updated in future work.
NB: In what follows, since disamenity index calibration relies on the model fit and is not computed a priori (contrary to other parameters), the options set in the preamble should be the same as the ones used in the main script, so that the calibrated values are in line with the structural assumptions used there.
We start with a general (not location-specific) calibration
[41]:
# We define a range of disamenity values which we would like to scan,
# and arrange them in a grid
# NB: as for gravity parameter, we set the range by trial and error
list_amenity_backyard = np.arange(0.55, 0.601, 0.01)
list_amenity_settlement = np.arange(0.55, 0.601, 0.01)
# list_amenity_backyard = [1]
# list_amenity_settlement = [1]
housing_type_total = pd.DataFrame(np.array(np.meshgrid(
list_amenity_backyard, list_amenity_settlement)).T.reshape(-1, 2))
housing_type_total.columns = ["param_backyard", "param_settlement"]
[42]:
# We initialize output vector
housing_type_total["formal"] = np.zeros(
len(housing_type_total.param_backyard))
housing_type_total["backyard"] = np.zeros(
len(housing_type_total.param_backyard))
housing_type_total["informal"] = np.zeros(
len(housing_type_total.param_backyard))
housing_type_total["subsidized"] = np.zeros(
len(housing_type_total.param_backyard))
[43]:
# We print the number of total iterations (to have an intuition of how long
# the process will take)
number_total_iterations = (
len(list_amenity_backyard) * len(list_amenity_settlement))
print(f"** Calibration: {number_total_iterations} iterations **")
** Calibration: 36 iterations **
We are going to compute the initial state equilibrium for each pair of parameters, and retain the one that best fits the observed number of households in informal settlements + backyards.
[44]:
param["precision"] = 0.01
import equilibrium.compute_equilibrium as eqcmp
for i in range(0, len(list_amenity_backyard)):
for j in range(0, len(list_amenity_settlement)):
# We set input values
param["amenity_backyard"] = list_amenity_backyard[i]
param["amenity_settlement"] = list_amenity_settlement[j]
param["informal_pockets"] = np.ones(24014) * param["amenity_settlement"]
param["backyard_pockets"] = (np.ones(24014)
* param["amenity_backyard"])
# We run the algorithm
(initial_state_utility,
initial_state_error,
initial_state_simulated_jobs,
initial_state_households_housing_types,
initial_state_household_centers,
initial_state_households,
initial_state_dwelling_size,
initial_state_housing_supply,
initial_state_rent,
initial_state_rent_matrix,
initial_state_capital_land,
initial_state_average_income,
initial_state_limit_city) = eqcmp.compute_equilibrium(
fraction_capital_destroyed,
amenities,
param,
housing_limit,
population,
households_per_income_class,
total_RDP,
coeff_land,
income_net_of_commuting_costs,
grid,
options,
agricultural_rent,
interest_rate,
number_properties_RDP,
average_income,
mean_income,
income_class_by_housing_type,
minimum_housing_supply,
param["coeff_A"],
income_baseline)
# We fill output matrix with the total number of HHs per housing
# type for given values of backyard and informal amenity parameters
housing_type_total.iloc[
(housing_type_total.param_backyard
== param["amenity_backyard"])
& (housing_type_total.param_settlement
== param["amenity_settlement"]),
2:6] = np.nansum(initial_state_households_housing_types, 1)
# We update the iteration count and print progress made
iteration_number = i * len(list_amenity_settlement) + j + 1
print(f"iteration {iteration_number}/{number_total_iterations}")
stops when error_max_abs <0.01: 13%|██████████████▍ | 129/1000 [00:03<00:23, 36.53it/s, error_max_abs=0.00783]
iteration 1/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:23, 37.32it/s, error_max_abs=0.007]
iteration 2/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:23, 36.84it/s, error_max_abs=0.007]
iteration 3/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.25it/s, error_max_abs=0.007]
iteration 4/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:23, 37.84it/s, error_max_abs=0.007]
iteration 5/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.30it/s, error_max_abs=0.007]
iteration 6/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:23, 37.82it/s, error_max_abs=0.007]
iteration 7/36
stops when error_max_abs <0.01: 13%|██████████████▍ | 129/1000 [00:03<00:22, 38.37it/s, error_max_abs=0.00787]
iteration 8/36
stops when error_max_abs <0.01: 13%|██████████████▌ | 130/1000 [00:03<00:22, 38.26it/s, error_max_abs=0.00699]
iteration 9/36
stops when error_max_abs <0.01: 13%|██████████████▌ | 130/1000 [00:03<00:22, 37.89it/s, error_max_abs=0.00737]
iteration 10/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.57it/s, error_max_abs=0.007]
iteration 11/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:23, 37.84it/s, error_max_abs=0.007]
iteration 12/36
stops when error_max_abs <0.01: 14%|████████████████ | 143/1000 [00:03<00:22, 38.27it/s, error_max_abs=0.00922]
iteration 13/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:23, 37.67it/s, error_max_abs=0.007]
iteration 14/36
stops when error_max_abs <0.01: 13%|██████████████▍ | 129/1000 [00:03<00:22, 38.05it/s, error_max_abs=0.00719]
iteration 15/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.17it/s, error_max_abs=0.007]
iteration 16/36
stops when error_max_abs <0.01: 13%|██████████████▌ | 130/1000 [00:03<00:22, 38.41it/s, error_max_abs=0.00927]
iteration 17/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.09it/s, error_max_abs=0.007]
iteration 18/36
stops when error_max_abs <0.01: 13%|██████████████▍ | 129/1000 [00:03<00:24, 35.38it/s, error_max_abs=0.00804]
iteration 19/36
stops when error_max_abs <0.01: 14%|███████████████▍ | 138/1000 [00:03<00:22, 38.03it/s, error_max_abs=0.00786]
iteration 20/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:04<00:29, 29.91it/s, error_max_abs=0.007]
iteration 21/36
stops when error_max_abs <0.01: 13%|██████████████▍ | 129/1000 [00:03<00:25, 34.43it/s, error_max_abs=0.00784]
iteration 22/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:26, 33.15it/s, error_max_abs=0.007]
iteration 23/36
stops when error_max_abs <0.01: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉| 999/1000 [00:28<00:00, 34.99it/s, error_max_abs=0.0111]
iteration 24/36
stops when error_max_abs <0.01: 13%|██████████████▍ | 129/1000 [00:03<00:24, 35.52it/s, error_max_abs=0.00744]
iteration 25/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:04<00:30, 28.11it/s, error_max_abs=0.007]
iteration 26/36
stops when error_max_abs <0.01: 13%|██████████████▍ | 129/1000 [00:03<00:25, 34.77it/s, error_max_abs=0.00992]
iteration 27/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:24, 35.82it/s, error_max_abs=0.007]
iteration 28/36
stops when error_max_abs <0.01: 13%|██████████████▍ | 129/1000 [00:03<00:26, 32.90it/s, error_max_abs=0.00717]
iteration 29/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:24, 36.07it/s, error_max_abs=0.007]
iteration 30/36
stops when error_max_abs <0.01: 13%|██████████████▌ | 130/1000 [00:03<00:23, 37.02it/s, error_max_abs=0.00699]
iteration 31/36
stops when error_max_abs <0.01: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉| 999/1000 [00:27<00:00, 36.19it/s, error_max_abs=0.0144]
iteration 32/36
stops when error_max_abs <0.01: 13%|██████████████▌ | 130/1000 [00:03<00:26, 33.23it/s, error_max_abs=0.00699]
iteration 33/36
stops when error_max_abs <0.01: 13%|██████████████▌ | 130/1000 [00:04<00:30, 28.81it/s, error_max_abs=0.00872]
iteration 34/36
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:24, 35.79it/s, error_max_abs=0.007]
iteration 35/36
stops when error_max_abs <0.01: 13%|██████████████▍ | 129/1000 [00:03<00:23, 36.89it/s, error_max_abs=0.00719]
iteration 36/36
[45]:
# We compute the error between simulated and observed number of households
# in each housing type (without RDP, which is exogenously set equal to data)
distance_share = np.abs(
housing_type_total.iloc[:, 2:5] - housing_type_data[None, 0:3])
# We define the score that we want to minimize as the sum of the errors for
# informal backyards and informal settlements
distance_share_score = (
distance_share.iloc[:, 1] + distance_share.iloc[:, 2])
# We select the arguments associated with the minimum
which = np.argmin(distance_share_score)
min_score = np.nanmin(distance_share_score)
calibrated_amenities = housing_type_total.iloc[which, 0:2]
[46]:
# We update parameter vector (after ensuring that param["amenity_backyard"] is
# bigger than param["amenity_settlement"])
param["amenity_backyard"] = calibrated_amenities[0]
param["amenity_settlement"] = calibrated_amenities[1]
# We print the calibrated values
print("amenity_backyard = " + str(param["amenity_backyard"]))
print("amenity_settlement = " + str(param["amenity_settlement"]))
# We save them
np.save(path_precalc_inp + 'param_amenity_backyard.npy',
param["amenity_backyard"])
np.save(path_precalc_inp + 'param_amenity_settlement.npy',
param["amenity_settlement"])
amenity_backyard = 0.5900000000000001
amenity_settlement = 0.5700000000000001
Calibrate location-specific disamenity index
[47]:
# Default is set to 1 but can be changed if we fear overfit of the model
import equilibrium.compute_equilibrium as eqcmp
if options["location_based_calib"] == 1:
# We start from where we left (to gain time) and compute the
# equilibrium again
# We first initialize input values
index = 0
index_max = 50
metrics = np.zeros(index_max)
param["informal_pockets"] = np.zeros(24014) + param["amenity_settlement"]
save_param_informal_settlements = np.zeros((index_max, 24014))
metrics_is = np.zeros(index_max)
param["backyard_pockets"] = np.zeros(24014) + param["amenity_backyard"]
save_param_backyards = np.zeros((index_max, 24014))
metrics_ib = np.zeros(index_max)
# We run the algorithm
(initial_state_utility,
initial_state_error,
initial_state_simulated_jobs,
initial_state_households_housing_types,
initial_state_household_centers,
initial_state_households,
initial_state_dwelling_size,
initial_state_housing_supply,
initial_state_rent,
initial_state_rent_matrix,
initial_state_capital_land,
initial_state_average_income,
initial_state_limit_city
) = eqcmp.compute_equilibrium(
fraction_capital_destroyed,
amenities,
param,
housing_limit,
population,
households_per_income_class,
total_RDP,
coeff_land,
income_net_of_commuting_costs,
grid,
options,
agricultural_rent,
interest_rate,
number_properties_RDP,
average_income,
mean_income,
income_class_by_housing_type,
minimum_housing_supply,
param["coeff_A"],
income_baseline)
# We set the maximum number of iterations
number_total_iterations = index_max
# Then we optimize over the number of households per housing type
# PER PIXEL, and not just on the aggregate number (to acccount for
# differing disamenities per location, e.g. eviction probability,
# infrastructure networks, etc.)
# To do so, we use granular housing_types variable (from SAL data) instead
# of aggregate housing_types variable
for index in range(0, index_max):
# INFORMAL SETTLEMENTS
# We initialize output vector
diff_is = np.zeros(24014)
for i in range(0, 24014):
# We store the error term
diff_is[i] = (housing_types.informal_grid[i]
- initial_state_households_housing_types[2, :][i]
)
# We apply an empirical reweighting that helps convergence
adj = (diff_is[i] / (np.nanmax(diff_is) * 100))
# We increase the amenity score when we underestimate the nb of
# households
param["informal_pockets"][i] = param["informal_pockets"][i] + adj
# We store iteration outcome and prevent extreme sorting from
# happening due to the amenity score
metrics_is[index] = sum(np.abs(diff_is))
param["informal_pockets"][param["informal_pockets"] < 0.05] = 0.05
param["informal_pockets"][param["informal_pockets"] > 0.99] = 0.99
save_param_informal_settlements[index, :] = param["informal_pockets"]
# INFORMAL BACKYARDS
# We initialize output vector
diff_ib = np.zeros(24014)
for i in range(0, 24014):
# Note that we add an option depending on whether we restrict
# ourselves to informal backyards (default) or all kinds of
# backyards (not warranted given the standardized structure
# assumed in the model)
if options["actual_backyards"] == 1:
diff_ib[i] = (
housing_types.backyard_informal_grid[i]
+ housing_types.backyard_formal_grid[i]
- initial_state_households_housing_types[1, :][i])
elif options["actual_backyards"] == 0:
diff_ib[i] = (
housing_types.backyard_informal_grid[i]
- initial_state_households_housing_types[1, :][i])
# We help convergence and update parameter
adj = (diff_ib[i] / (np.nanmax(diff_ib) * 100))
param["backyard_pockets"][i] = (
param["backyard_pockets"][i] + adj)
# We store iteration output and prevent extreme sorting
metrics_ib[index] = sum(np.abs(diff_ib))
param["backyard_pockets"][param["backyard_pockets"] < 0.05] = 0.05
param["backyard_pockets"][param["backyard_pockets"] > 0.99] = 0.99
save_param_backyards[index, :] = param["backyard_pockets"]
# We retain the sum of the errors as our minimization objective
metrics[index] = metrics_is[index] + metrics_ib[index]
# We run the equilibrium again with updated values of
# informal/backyard housing disamenity indices, then go to the next
# iteration
(initial_state_utility, initial_state_error,
initial_state_simulated_jobs,
initial_state_households_housing_types,
initial_state_household_centers,
initial_state_households, initial_state_dwelling_size,
initial_state_housing_supply, initial_state_rent,
initial_state_rent_matrix, initial_state_capital_land,
initial_state_average_income, initial_state_limit_city
) = eqcmp.compute_equilibrium(
fraction_capital_destroyed, amenities, param, housing_limit,
population, households_per_income_class, total_RDP,
coeff_land, income_net_of_commuting_costs, grid, options,
agricultural_rent, interest_rate, number_properties_RDP,
average_income, mean_income, income_class_by_housing_type,
minimum_housing_supply, param["coeff_A"], income_baseline)
iteration_number = index + 1
print(f"iteration {iteration_number}/{number_total_iterations}")
stops when error_max_abs <0.01: 13%|██████████████▍ | 129/1000 [00:03<00:25, 34.75it/s, error_max_abs=0.00992]
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.40it/s, error_max_abs=0.007]
iteration 1/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.96it/s, error_max_abs=0.007]
iteration 2/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 39.02it/s, error_max_abs=0.007]
iteration 3/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.70it/s, error_max_abs=0.007]
iteration 4/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.77it/s, error_max_abs=0.007]
iteration 5/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:23, 37.32it/s, error_max_abs=0.007]
iteration 6/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.79it/s, error_max_abs=0.007]
iteration 7/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 39.40it/s, error_max_abs=0.007]
iteration 8/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.58it/s, error_max_abs=0.007]
iteration 9/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 39.19it/s, error_max_abs=0.007]
iteration 10/50
stops when error_max_abs <0.01: 24%|██████████████████████████▊ | 239/1000 [00:06<00:20, 37.40it/s, error_max_abs=0.00192]
iteration 11/50
stops when error_max_abs <0.01: 33%|████████████████████████████████████▉ | 330/1000 [00:12<00:26, 25.71it/s, error_max_abs=0.00928]
iteration 12/50
stops when error_max_abs <0.01: 13%|██████████████▍ | 129/1000 [00:03<00:25, 33.79it/s, error_max_abs=0.00868]
iteration 13/50
stops when error_max_abs <0.01: 13%|██████████████▌ | 130/1000 [00:03<00:20, 41.65it/s, error_max_abs=0.00699]
iteration 14/50
stops when error_max_abs <0.01: 65%|████████████████████████████████████████████████████████████████████████▍ | 647/1000 [00:17<00:09, 37.48it/s, error_max_abs=0.00237]
iteration 15/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:21, 40.77it/s, error_max_abs=0.007]
iteration 16/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:21, 40.48it/s, error_max_abs=0.007]
iteration 17/50
stops when error_max_abs <0.01: 42%|███████████████████████████████████████████████▎ | 415/1000 [00:10<00:14, 39.24it/s, error_max_abs=0.007]
iteration 18/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:23, 37.47it/s, error_max_abs=0.007]
iteration 19/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.33it/s, error_max_abs=0.007]
iteration 20/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:23, 36.69it/s, error_max_abs=0.007]
iteration 21/50
stops when error_max_abs <0.01: 13%|██████████████▉ | 133/1000 [00:03<00:24, 34.72it/s, error_max_abs=0.00584]
iteration 22/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:23, 36.56it/s, error_max_abs=0.007]
iteration 23/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:24, 35.60it/s, error_max_abs=0.007]
iteration 24/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.37it/s, error_max_abs=0.007]
iteration 25/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.45it/s, error_max_abs=0.007]
iteration 26/50
stops when error_max_abs <0.01: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉| 999/1000 [00:25<00:00, 38.89it/s, error_max_abs=0.028]
iteration 27/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:23, 36.53it/s, error_max_abs=0.007]
iteration 28/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:23, 37.21it/s, error_max_abs=0.007]
iteration 29/50
stops when error_max_abs <0.01: 13%|██████████████▍ | 129/1000 [00:03<00:21, 40.71it/s, error_max_abs=0.00818]
iteration 30/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:02<00:18, 47.14it/s, error_max_abs=0.007]
iteration 31/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:02<00:18, 46.71it/s, error_max_abs=0.007]
iteration 32/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:20, 42.73it/s, error_max_abs=0.007]
iteration 33/50
stops when error_max_abs <0.01: 13%|██████████████▍ | 129/1000 [00:03<00:21, 41.38it/s, error_max_abs=0.00755]
iteration 34/50
stops when error_max_abs <0.01: 19%|█████████████████████▊ | 190/1000 [00:04<00:18, 43.76it/s, error_max_abs=0.01]
iteration 35/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:02<00:19, 43.83it/s, error_max_abs=0.007]
iteration 36/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:20, 42.39it/s, error_max_abs=0.007]
iteration 37/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:20, 41.85it/s, error_max_abs=0.007]
iteration 38/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:02<00:19, 44.37it/s, error_max_abs=0.007]
iteration 39/50
stops when error_max_abs <0.01: 43%|████████████████████████████████████████████████▌ | 434/1000 [00:09<00:12, 43.97it/s, error_max_abs=0.00395]
iteration 40/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.36it/s, error_max_abs=0.007]
iteration 41/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 39.19it/s, error_max_abs=0.007]
iteration 42/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:22, 38.68it/s, error_max_abs=0.007]
iteration 43/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:23, 36.36it/s, error_max_abs=0.007]
iteration 44/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:21, 39.84it/s, error_max_abs=0.007]
iteration 45/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 131/1000 [00:03<00:21, 39.86it/s, error_max_abs=0.00956]
iteration 46/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:21, 40.54it/s, error_max_abs=0.007]
iteration 47/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:21, 40.14it/s, error_max_abs=0.007]
iteration 48/50
stops when error_max_abs <0.01: 13%|██████████████▋ | 129/1000 [00:03<00:21, 40.57it/s, error_max_abs=0.007]
iteration 49/50
stops when error_max_abs <0.01: 25%|███████████████████████████▉ | 249/1000 [00:06<00:18, 40.01it/s, error_max_abs=0.00924]
iteration 50/50
[48]:
# We pick the set of parameters that minimize the sum of absolute diffs
# between data and simulation
score_min = np.min(metrics)
index_min = np.argmin(metrics)
# We update the parameter vector
param["informal_pockets"] = save_param_informal_settlements[index_min]
param["backyard_pockets"] = save_param_backyards[index_min]
# We save values
np.save(path_precalc_inp + 'param_pockets.npy',
param["informal_pockets"])
np.save(path_precalc_inp + 'param_backyards.npy',
param["backyard_pockets"])